KB2151749 - ESXi Host Fails With PSOD After Upgrading to 6.5
Sometimes the upgrades pose problems
Operating systems evolve all the time. This also includes ESXi. The easiest way to keep up with the latest and greatest is to perform upgrades. Each time there is a custom risk that we can be affected, unfortunately, by new bugs that were not discovered before release.
Simple use of 10GB NICs can cause a host failure with PSOD
I want to present such case when upgrades can disturb, under certain circumstance, the availability of the environment.
Let's take as example the upgrade of ESXi host to version 6.5 and one of the VMware Knowledge Base articles related to it (KB2151749).
Nowadays 10GB NICs are used everywhere as they are providing great bandwidth, lower cost, increased scalability, and simplified management.
Upgrading to ESXi version 6.5 will cause a host failure with PSOD. Just the simple combination of these 2 factors, 10GB NIC and ESXi 6.5 can lead to an outage with the following backtrace:
Why such a usual and simple combination can interrupt the availability of the ESXi host?
According to the KB, “This issue occurs because the Netqueue commit phase abruptly stops due to a failure of hardware activation of a Rx queue. As a result, the Internal data structure of the Netqueue layer's could go out of sync causing a host PSOD.”
OK, we can see that NetQueue is the deciding factor of this outage.
What is NetQueue and how it is working
The 10GB NICs provides lots of benefits but they also have a downside. This may come by the way it is configured, as most of the time it will be used as a shared resource (it’s unlikely to use 10GB NIC per VM in the host).
At this point a queuing mechanism is needed, so NetQueue will have the role to deliver network traffic to the system in multiple receive queues that can be processed separately, allowing processing to be scaled to multiple CPUs, improving receive-side networking performance. By this the bottleneck is eliminated as each vNIC will have his own queue.
I found a nice article explaining in details how NetQueue works and I suggest you to read it: "Using VMware NetQueue to virtualize high-bandwidth servers" by George Crump. I want to thank George for such a detailed presentation.
Fixes and workarounds
So let’s go back to our KB. We know the problem but how we can fix it?
VMware recommendation is to apply the ESXi 6.5 P02 or to use one of the two workarounds available:
- Downgrade to ESXi 6.0 U2 - looks like a step back
- Disable NetQueue - here we have a caution: Disabling NetQueue can cause performance issues with network IO intensive virtual machines
Since both workarounds doesn’t look optimal probably it is time for a new update of hosts to ESXi 6.5 P02.
But, can we expect that P02 is working perfect and no other issues might encounter? Hard to tell, as problem might appear form simple combination of components as we have seen above or multiple factors.
The number of KB’s related to known issues that might affect the environments are many but hard to discover them in time to apply the resolution.
How proactive automation tools can help to avoid outages
A great support to find such issues described in Knowledge Base articles it is provided by Runecast Analyzer.
The PSOD described in the article can be easily avoided if we know about it in advance, if someone could match our environment configurations and the KBs articles and point where the problems might occur.
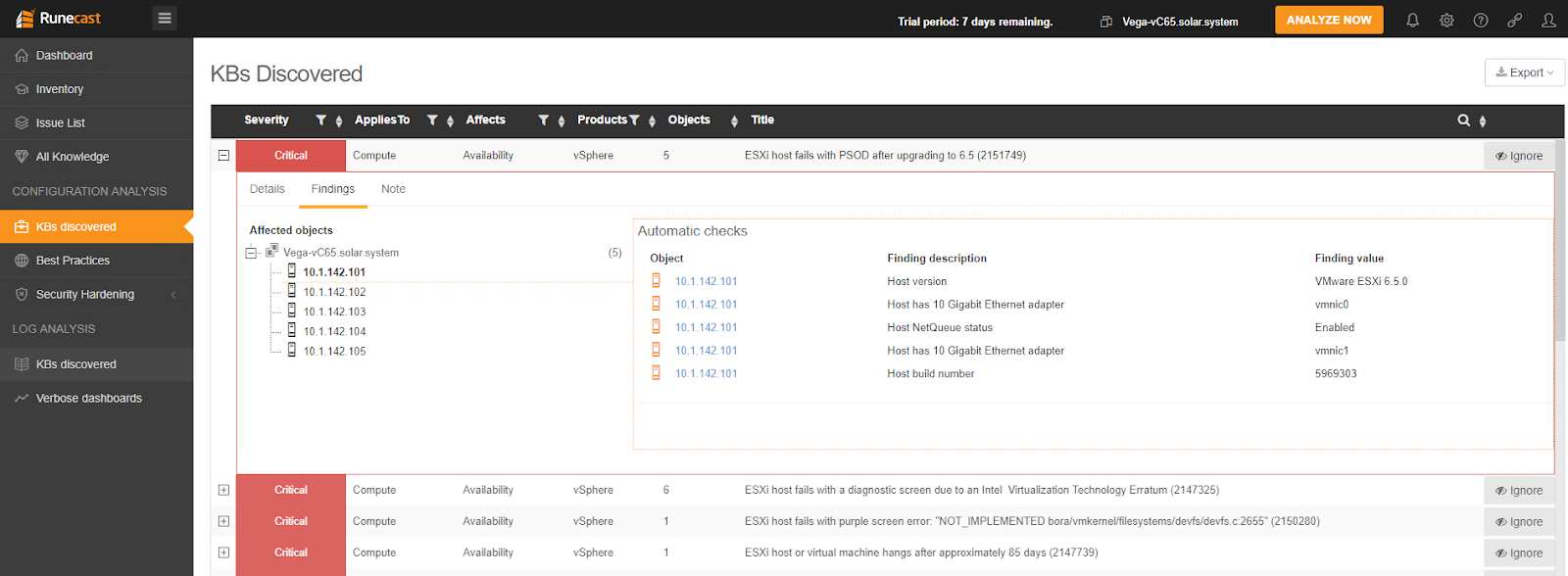
Runecast provides proactive fault avoidance to minimize the risk of virtualized datacenter downtime and security breaches. The Analyzer is an automated system that correlates VMware vSphere and vSAN configurations and logs with the official VMware repository of known issues, best practices and security auditing rules.
Ionut Radu
Data Scientist Engineer
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑
Click to view larger image ↑